

An engineering strategy goes beyond your OKRs (if that’s what you use for goal setting). It goes into where you want the organization to be in the next few years. As a leader, you need to decide the short-term tactics you wish to use and your long-term plays. A strategy doesn’t necessarily need to be written down if the leaders understand what you want to do.
Setting a strategy requires you to invest where you will spend your time and resources. It requires you to consider what kind of culture you want and what steps you can take to get there. An engineering strategy is about consistently conveying your message and rallying people around it.
When I think about an engineering strategy, I look at it in several parts that will make up the whole. There is the technical strategy, which is about the technical long-term things your organization will do. Next up is the people. Who do you want in place to drive the organization forward? Lastly is the cultural strategy, which is about what kind of mindset you want your organization to have.
1. Technical Strategy
There is the technical strategy, which is about what things from a technical perspective will you do to make it better longer term for the engineering team to perform better. It could be cloud-native, on-premise, Kubernetes, platforms, languages, or AI. Given the business strategy, this is about how you will support the organization long-term.
Let me briefly explain a technical strategy we’ve undertaken in Bukalapak. It’s one of the multifaceted approaches we’ve taken to change the path forward for engineering truly. My previous post on Innovation at Scale explains that it’s about the platform. Most companies eventually build a platform to support their engineers.
Building a Platform
Eventually, I believe most companies (that are big enough) will build their own platform to support their developers. The word platform is a bit loaded, but in this case, I mean a series of internal interfaces that allow engineers not to repeat themselves. This can range from identity and access management to fraud, payments, logging, and monitoring.
Usually, this is supported by a non-customer-facing team, developer experience, or platform. Their “customers” are the engineers themselves and their goal is to build the interfaces generic enough that any team in the company can use them but also specific to the company’s needs.
At Bukalapak, we decided to build a platform when we noticed from the business direction that we were moving towards specialized marketplaces. This meant that we needed to build up new marketplaces and will continue to build up new marketplaces. We needed to ensure that our limited engineering team had a consistent experience across any of these incubators and that the technology used was homogeneous to allow any engineer to quickly pick up a product when needed at the different life stages.

In general, you won’t need to build a platform. Investing your time and effort in this won’t make any sense for most small-to-medium-sized companies. But when you’re supporting hundreds (or thousands) of engineers, you will likely be looking for how you can improve the effectiveness of the entire organization. As a leader, it will be your job to recognize patterns across the organization and use those to develop your mental model for how this platform may look.
Handling Legacy
Legacy code or projects are a tricky business. We are somehow trained to want to refactor legacy even if it is working because it was a) either written by us a long time ago and our standards and practices have changed or b) written by someone else, and we have trouble reading their code. This often translated to engineers calling it spaghetti code or technical debt.
When I think about approaching legacy code, I don’t like to look at big bangs like “Let’s rewrite this service.” Usually, this ends up with a longer-than-expected timeline and results in a new legacy service. It doesn’t bring any product/business value (other than developer happiness/potential unproven velocity gains). As long as the legacy code is well covered with tests, we can gradually refactor it. This reduces the risk of a project running over budget and introducing new bugs (or removing old bugs that were features). By gradually refactoring, I mean as we touch different parts of the code, we leave it better/cleaner than it was.
Migration Plans
If your company is ancient (in tech years), you might eventually have to handle some migration due to the long-term support of whatever you’re building being discontinued. This might be because you should be compliant and reduce the risk of security flaws or it could be that the version you’re using no longer compiles/is not found on the public web.
When planning such migrations, primarily when they affect many parts of the system, you must do some pre-work. What are the changes when you upgrade? What are the deprecated APIs or interfaces and what are the new ones? Do you need to rework your application code as well? This investigative work needs to be done to reduce the risk.
You’ll likely need to deliver on regular product value work simultaneously. You need to prove that this investment is worth it to your stakeholders. For example, an ISO27001 audit may raise concerns over out-of-shelf technologies that no longer receive security patches. Ensure you plan this work to go alongside your regular delivery. Yes, it may take longer than expected, but you’ll still add business value.
Stack Choice
Stack choice of your company may depend on the size and throughput needs (how low-level you need to go). But, most likely unless you’re looking to optimize your costs as a start-up or a growing company, you should probably continue with the stack you have (unless it’s hard to hire for).
Hiring is one of the main reasons I would potentially look to change stack. Imagine you use COBOL (lousy example – I know), and you’re looking to hire hundreds of engineers over the next year. Likely, it will be hard for you to find engineers experienced in it and also hard for you to find engineers willing to work with it. Why would an engineer join your company using COBOL which they won’t be able to market beyond your company?
The scalability of the language is also something to consider. There are numerous examples of companies switching languages (let’s say from Ruby to Golang) as they try to optimize their costs. Once you reach a particular scale, it makes sense that you will have certain constraints. It’s why Facebook (Meta) eventually modified PHP.
What about legacy languages? As mentioned above, if it becomes hard to hire for your language or long-term support for the language is dropped, it may make sense to think about where to move. For example, the web (frontend) moves at a break-neck speed compared to the backend. If you’re still using Angular 1.X, you probably need to consider moving on.
Cloud Choice
The default of most start-ups is to go with the cloud. It’s pretty much implied if you have a customer-facing application or a Software as a Service that you’ll be hosting in one of the big three (AWS, GCP, and Azure). Why do we do this? One – it should reduce the need for additional manpower to maintain your own servers. Two – it allows for far more scalability and flexibility than server racks. However, you’ll probably notice your cloud bill grows with you as you grow (maybe even linearly – depending on how you’ve optimized your services).
Your cloud choice might be more business-driven rather than technology-driven. You’ll work with your business (or finance) team to negotiate multi-year contracts (at larger companies) with discounts. As a start-up, you might choose the cloud you’re most familiar with (or gives you the best free tier).
Once you scale, you might realize that some cloud services don’t have all the features you need, so you’ll be looking at a multi-cloud approach (increasingly becoming common as you optimize and cloud pricing discounts get less). For example, you may want to use ChatGPT but want more enterprise-like features. So, you’ll go through Azure because you don’t like the AI technologies produced by GCP and AWS.
To Build or to Buy
I was influenced heavily by someone in a previous organization who said: “Never buy something that is core to your value proposition as a business.” How you interpret that is up to you as a leader. What you might consider core to your business could be identity management. You might want to own all the data (and headaches) that come with identity and access management. However, some may end up using a SaaS like Auth0, Ping, or others as they don’t want to spend engineering time and resources on a problem that has been solved in the industry.
You’ll likely want to outsource as much as possible when starting. You don’t want to have to build the whole stack. This will include your cloud, access management, monitoring, logging, metrics, etc. Plenty of tools exist on the market that you can leverage to get the product out the door.
At some point, you may want to bring some of the tools in-house (build). At this stage of your lifecycle, you’ll probably be worried about profitability and how to save on excess costs by maintaining or building your version of (likely expensive) SaaS. If the product isn’t core to your values and costs little, I would keep it and let the SaaS continuously improve its offering (you can also negotiate). If you start to realize you need the data in-house and it’s becoming a hassle to get on calls with the vendor, then it’s probably time to move away.
You’ll notice I’ve avoided advising for or against building or buying too much. There’s a lot of context to make decisions that I won’t be able to give you. Each problem is unique and so will be your decision. As long as you’ve thought about it as a leader and it’s always in the back of your mind to reevaluate, you’re doing the right thing.
Security
As a product engineering leader, security tends to be the last priority. However, that doesn’t mean that I don’t think about it. I believe in shifting security left (as part of my overall cultural strategy, I believe engineers should be T-shaped). This means that security should be as much as possible into the overall build process as automated as possible. You want to make it easy for engineers to be security conscious and not block their work.
In some previous companies, I’ve found security to be on the outside of engineering. It’s usually an afterthought and only happens when an incident (like a data breach) occurs. If you build it into your pipelines, you’ll reduce the risk. As well, the tools will get better with time. An example is building SAST (Static Application Security Testing) into your merge requests as a blocking step (if it fails).
Another example is to coach engineers in defensive programming, where you secure all your inputs on the server side so that common attack vectors like SQL Injection cannot occur. You also want to train engineers to think about the principle of least privilege, especially with the cloud. By shifting the mindset left, the security team will have less work and (hopefully) not get in the way of product development.
Unfortunately, not everything can be automated yet. While some tools exist for unauthorized network detection or other anomalies within the system, you’ll probably still need a security team (red/offensive and blue/defensive) overseeing the organization and all your public (and private) endpoints. This is more important when you become a bigger target.
Security should not be left behind. It should also not be an afterthought. You’ll be in a much better position by shifting a lot of the responsibility left and automating as much as possible. This is driven a lot by your cultural strategy.
Monitoring and Reliability
There are plenty of tools out there for monitoring. It’s essential to know how your system performs and how that affects customer satisfaction. Most people will turn to SaaS to help them out – things like Datadog or NewRelic. I prefer this (as stated by the build vs. buy dilemma) as it’s not a core competency of the business (unless you’re selling monitoring software). This can get costly fast, so once the spending gets out of control for observability, you might consider building your own using open-source tooling.
Monitoring will help bring you data and observations that are quantifiable to your stakeholders. They will also allow you to bring automated alerts when things go wrong. I read once that having a software product (as a service) without monitoring is like walking deep in the jungle without a compass. How do you know when things go wrong unless your customers tell you? You want to know before your customers so you can already give them the message that you’re on it (if you have some SLA).
Regarding reliability, we’d all like to aim for 99.999% (triple 9) uptime, but this is approximately 26 seconds of downtime a month. As a startup (or even an established SaaS), that would be a nightmare to maintain. Going the other extreme – 99% uptime is 7 hours of downtime a month. That’s okay for a small start-up, but once you have hundreds or thousands of customers, it’s likely too low of a goal. 99.9% uptime is a good compromise for most at 43 minutes of downtime a month. This is enough for one or two incidents with a quick recovery (MTTR). When each minute is measured in thousands, you might go for one more 9.
Measuring reliability is not just your uptime but also how fast you detect incidents (MTTD) and how fast you recover (MTTR). Observability is not just the APM (Application Performance Monitoring) but also your analytics and business metrics (re: custom events). i.e., Your system might be up – but there’s a bug, and customers cannot pay. Only your business metrics would see this drop. Again, I would shift this to product engineering and away from devops. We should care about the systems and their performance.
Quality
Quality is a tricky subject. I see value in quality engineering (or software development engineering in test), but at the same time, I feel if we have a quality team, it allows the product engineers to shift the responsibility to quality and away from themselves. This shift of responsibility is what reduces the accountability of the team and the code that they produce. Yes, you’ll probably catch more bugs with a handover to quality, but you’ll also reduce the ownership of the engineers and the accountability for shitty code.
Engineers are not all-seeing and usually do not know how their change will impact a more extensive system. I see value in quality gates and again like security, automation everywhere. By shifting quality left, engineers will invest more in automation to prevent incidents. These need to be blocking steps in your build pipelines.
At some point, you receive diminishing returns – especially for test coverage. I don’t think teams should aim for 100% test coverage automation. A more practical number would be 80%. This should cover the major branches in the code and the most common cases. You may end up with edge cases, which will then head into a bucket called regression tests. These are tests designed to prevent the same incident from happening again.
UI tests are the heaviest tests to run. They are also the most notoriously flaky tests as they tend to test your entire system and rely on naming conventions. They are also the most critical for a “happy path.” This means you test your core functionality but probably not the edge cases. This reminds me of a joke (sorry to my quality engineers out there):
QA Engineer walks into a bar. Orders a beer. Orders 0 beers. Orders 9999 beers. Orders a penguin. Orders -1 beers. Orders a wegjfgeyj.
Source: The Internet
Data
Data is something that I’m seeing more and more of a “shift right.” That data used to be owned by product engineers but is now heading towards large central platforms owned by a dedicated data engineering team. This is because it’s becoming increasingly complex as we add huge data lakes with different data analytics platforms where the data needs to be extracted from individual databases and transformed into business-friendly data where we can apply some machine learning on top of it to gather patterns and make predictions.
I suspect the data strategy will continue as the role becomes increasingly specialized and the tooling remains separate. Think of it like the BA (Business Analyst) roles of the past. These engineers and scientists will work with business operations (and product managers) to understand how the business is doing.
2. People Strategy
Do you have the right people in place? Do you have the proper structure for your organization to succeed? Do you have the right skills? These are all good questions you need to ask yourself whether you are an engineering leader or any other leader. The people on your team are your best (or worst) asset.
Engineering Structure
Engineering structures come in many different forms. Most companies I’ve worked at do a double helix model, whereby you have your competence (engineering) leader, and your business (product) leader in each team. This dual structure allows the direct manager to work on the engineers’ career pathways and for the product to concentrate on growing the business. As an engineer, you will be working with both leaders daily.
When we look at the organization chart with the double helix model, we see a parallel grouping – one side is product, and one side is engineering. Engineers report to engineering managers, then engineering directors, and so on up to the most senior responsible engineering leader. The same follows for product – product managers report to product leads/head of product who report to the most senior product lead.
The dual structure means that each level has to align. i.e., a VP of Engineering has to align with the VP of Product in terms of priorities and execution. A Director of Engineering should align with a Senior/Lead Product Manager. An Engineering Manager should align with a Product Manager.
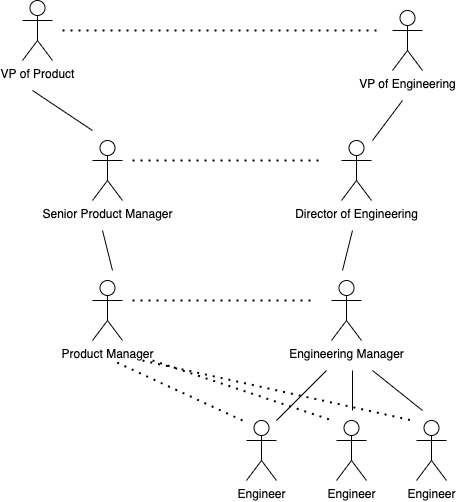
It’s not always an easy structure to follow. There can be a conflict of prioritization if the company has separated technical and product OKRs. Resources can be misaligned if engineering and product have different interpretations of their performance appraisals (especially if the engineering team is monitored on metrics and not left to solve problems). Ultimately, the engineer will follow his (competence) manager’s guide on what to do during a conflict of priorities as this is the person who will decide their performance.
The dual helix structure is effective because it allows for a dotted-line approach to teams. Yes, you have two managers, but you know you will be supported with your career and the business will be supported. Generally, teams are aligned on what they will be working on, but this alignment needs to be maintained. This structure can be ineffective if you want to move fast, but one organization wants to do something else.
Another twist on the double helix model I’ve seen is separate engineering and product organization up to a business level. For example, you are a company offering SaaS with multiple products (let’s take employee productivity as an example). We offer performance appraisal software, employee net promoter score software, and employee onboarding software. Three business units. The twist is that these three engineering organizations report to different business leads. It’s effective because it gets the engineering and product organization to focus on their problem. It’s ineffective because it creates local optimizations and increases the chance that you’ll be working on the same problem as other teams.

What about the other structures? What happens when your engineering team reports only to engineering with no product? I’ve only seen this in platforms or research and development teams. i.e., cost centers and not profit centers. Without someone to prioritize business needs, they end up working on great things – but things that may not be needed. For example, you spin out an AI team to investigate this GPT technology. They may come back with the best bot to replace your customer service team, but without a representative from the business side, you find out they built something to satisfy how they would interact with the bot – rather than what your customers need.
Lastly, I want to mention if you have multiple sites (re: offices) that your structure may be using some of the above but with some localization. For example, you may want your product and engineering teams to work together at each site, so you must hire both roles locally. Eventually, someone will report to the head office. Ideally, each site has a different focus, allowing for teams to interact with groups in their office rather than having teams spread out (or engineers distributed). The downside of site-based products is that localized engineering practices will turn up and ways of working will likely differ between offices, leading to inter-office conflicts (us versus them mentality).
Growth
You need to ensure you have a strategy for growing your team. Do you have the proper leveling in place for your organization? Will you make it hard to hire engineers with your titles? When I think about an engineering growth strategy, you want to ensure you keep people engaged, but you also don’t want anything too complex.
So far, most organizations I’ve been in have something akin to intern, junior, intermediate, or senior regarding a standard career path. These may end up with titles like Member of Technical Staff I (junior), II, III (Senior), Software Engineer I, II, III, or Software Developer. You may also see no titles but have levels internally (we’re all just Software Engineers).
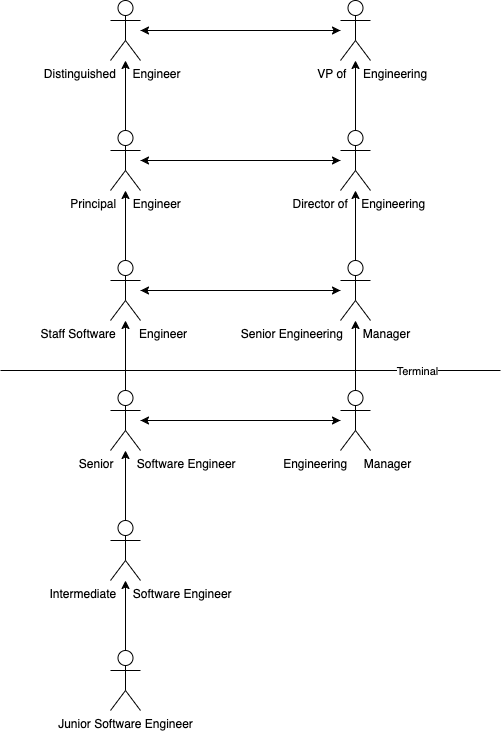
Where things deviate is what is known as the terminal level and beyond. The terminal level is where you’ll see most engineers at a company end up. From my observations, this is almost always Senior Software Engineer. After this level, things get murky. Why? Because not every company has a dual/tri track for engineering leadership.
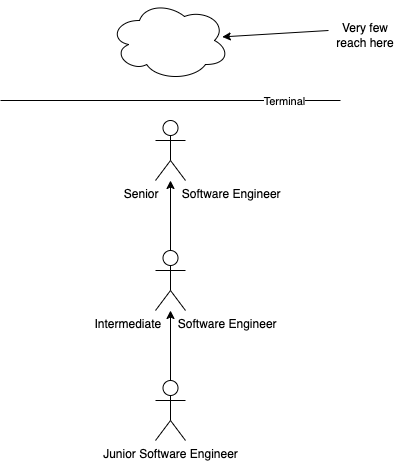
What is the traditional view on growth? Eventually, you reach a Senior Software Engineer. After that, the only path forward is management. This leads to engineers becoming managers who are maybe not the best suited. You also lose strong problem solvers who could do more with all their context and knowledge to the management path. All engineers see is that they need to be managers to go further. This view of growth is still heavily prevalent in South East Asia (from my observations).
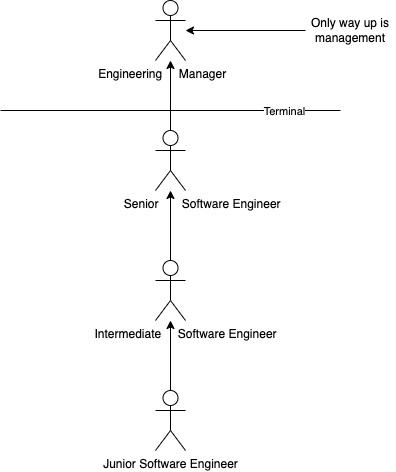
How about a dual track? What is that? The dual track is a new view on growth whereby you can be an IC (Individual Contributor) and have a similar growth path to managers. For example, you might have Staff, Principal, or Distinguished Engineers at the same level as Senior Engineering Managers, Heads of Engineering, or VPs of Engineering. This duality allows engineers to impact the company without having the direct authority of being a manager. These engineers are rewarded for driving company (or tribe) initiatives. Likely, you don’t need this if you’re a 20-person start-up! But you should be thinking about it if you’re snowballing.
And the tri track? What’s different about that? This is a less discussed track as some companies don’t have these positions (the engineers end up being Staff/Principal, etc.). Here, you can add an architect role, which differs from an engineering role as they look towards the company and work at a component level from an architecture perspective. They might be doing less POC (Proof of Concept) work than the Principal Engineers and have a slightly different reporting structure (outside Product Engineering).
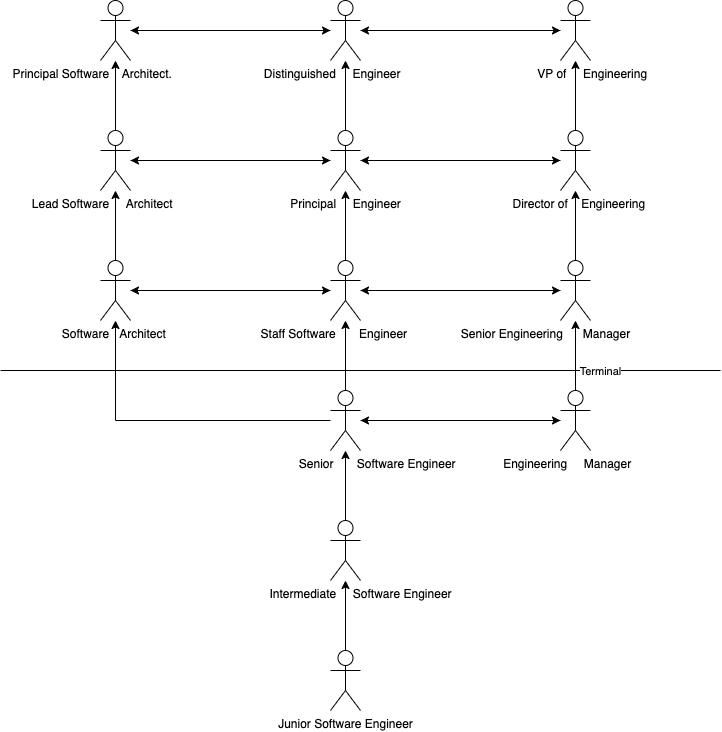
Overall, you need to consider your engineering growth (and I don’t mean headcount). You need clear guidelines for expectations at each level (prefer concise, simple definitions). When your team is big enough, you must know how everyone can grow and learn at your company.
Hiring
How you hire will set the engineering organization’s culture, growth, and future performance. With your hiring strategy, you need to consider how you interview, when you interview, how long the process will take, and how you will treat candidates. You’ll also need to work within your budget for what positions you need – not for now – but for a year down the line.
How will you interview? Will you include an online test (cognitive/behavioral/technical)? At what stage is the test going to be sent out? You need to think about what kind of skills you want to hire and how you will test for those signals. For example, let’s take a mid-level software engineer. You would expect this engineer to have exposure to different architectures already and be able to develop some basic solutions to an architecture problem. You may also expect them to have database exposure and be able to design a database for a given situation. You may not expect them to have worked on leading projects. When you come up with the skills you want to hire for (similar to your competencies across your growth), you can design the pipeline.
When will you interview? If you’re hiring interns or graduates (which I recommend for balanced teams and growing not just the junior engineers but the senior engineers through the mentor-mentee relationship), you should probably be on the lookout for graduation dates and starting your search before then. If you’re in Indonesia, you’ll ideally want to be looking any time after Idul Fitri (when people receive their THR). If you’re looking for someone more senior, you probably want to start earlier rather than later.
How are you going to monitor hiring and onboarding? How long will your process take? While you’re interviewing, your candidates are probably also interviewing elsewhere. The faster your approach is, the better it is for everyone. I’ve seen that engineering interviews are usually multiple rounds with at least one online test (or a take-home test). There’s a cultural fit, live coding (peer coding) exercises, and architecture rounds. Not all these are strong signals – for example, you might expect a staff/senior engineer who is not job-hunting to do worse on the online test than a fresh graduate.
How do you know if the hire is a success? As I said above, what metrics will you use to measure success? Will you check up on the performance during the probation period? How do you ensure everyone is set up for success? A bad hire will cost money and time invested into them.
Hire for the future. You might need someone now, but will you need this person in 12 months? Do you have enough work to sustain and grow their performance? Do you still have enough stretch work for the team to demonstrate that they’re learning and growing in their roles? Can you work with your stakeholders to prioritize the work rather than add more people?
Performance
Performance appraisals are hard to avoid. Some companies have successfully got rid of them, but most companies follow what they call a meritocracy, whereby your abilities and achievements promote you at the company. For performance, you must look beyond what your talent/people/HR team has set for the company. Engineering performance is one of those hard-to-define buckets, but not impossible.
I’ve seen a bit of noise recently, thanks to several articles. One of the realities of software engineering is that we have both output and outcomes. Our output is things we work on daily – the code, the tickets, the documentation. Our outcomes are our business impact after our output (together with the product) – revenue from customer happiness, new features, decreased churn thanks to a faster UX experience, and new products. Outcomes are much harder to measure because you can’t point to an individual and say they did it (unless they did – but software engineering is a team sport).
This problem reminds me of the business parable on the internet about the experienced engineer. He comes to the client’s site and wacks a pipe with a hammer to get it working again. He charges an outrageous amount, and the client demands he itemize it. $5 for the hammer. $4495 for knowing where to wack.
How is this relevant? Imagine an experienced engineer coming in and solving a team’s problem for months with only one line of code after reading through their code for a couple of weeks, where the team has been working tirelessly for months deploying changes and fixes. If you compare the team’s output to the engineer, the team would likely perform better. Whereas if you look at the outcome and impact, the experienced engineer did more.
So, how do you measure individual performance at companies that follow meritocracy and value what you’ve brought to the company? Most companies use some 360 review process, whereby you have a self-reflection in which you assess your performance, you have peer feedback, in which your peers give you feedback on what you’ve done and how you’ve done it, and you have the manager’s feedback (from both product and engineering). These are then calibrated across the company to ensure consistency and less favoritism.
You can have auxiliary data from the output and the outcomes to help guide some decisions. Is a team less valuable because they’re working on a product that generates less revenue than the other products? How about if you have platform teams that are cost centers and don’t generate revenue directly but contribute to the company’s overall productivity? Always use the data in context and never as a primary measure. Just because someone writes more code doesn’t mean they are more effective than the other engineers. Efficiency does not equal effectiveness. Remember that.
3. Cultural Strategy
When I think of cultural strategy, I look at the organization’s behaviors or traits and how they affect how we work. It’s worth talking to engineers directly, getting feedback from pulse surveys, or what is called out during performance appraisals. I also listen to our other functions to see how we interact and what is missing. There are a lot of insights from different places that you need to gather to help form your strategy here.
T-Shaped
One of the first things I noticed when joining an Indonesian company is the specialization and the “not-my-job” mentality. Most engineers prefer to stay front-end, app, back-end, or infrastructure. They would rather not venture into other specialties to become T-shaped engineers (or full-stack) because it is more work and responsibility without additional compensation.
Coming from a product-engineering background, this mentality shows that they don’t care enough about the product to take ownership and drive product enhancements vertically. The engineers would rather have a hands-off approach to product development and let the product managers “own” the product while they code.
The cultural shift we needed to make was to change the mindset. You can be the product owners, but we need our leaders to demonstrate this. We needed our leaders to care more about product and business results and how engineering enables those. Previously, there was a clear separation between engineering and product goals. Now, we head into our planning with product and engineering partnering together.
Another shift we needed to make was the unbundling of the specialization. Yes, some engineers can be more specialized in one stack than the other, but when working in a product squad, an engineer should be able to pick up multiple stacks to deliver an end-to-end experience. To achieve this, we looked at how we can help engineers to gain experience. We delivered training on multiple stacks. We changed the way performance was assessed.
Ownership and Accountability
This is important to me as a product engineer and the culture I want to create. When I talk about ownership, I don’t just mean the code or the services themselves. I mean ownership of the entire product and business. As a product engineer, you should be (somewhat) interested in what you’re working on. Maybe it’s not your life’s mission, or you don’t have the same passion as the founders, but you should still be (somewhat) excited by what you release (or if not the product then the impact that the product has). Yes, you may only be releasing accounting software so it’s hard to get excited by it – but what you can get behind is the fact that you are helping businesses around the world succeed.
As an owner, you take pride in your work. That means that everything from A-Z you care about whether that’s security, quality, infrastructure, or user experience. It all falls to you. Even more so as a product engineering leader (IC or manager). You can speak up when things look wrong or turn to dark patterns. You may not be an expert, but you’re willing to learn.
However, with ownership comes accountability. You and your team are accountable for the product you’re developing. If you deviate from well-known or widely accepted practices, you’re willing to take responsibility when things go wrong and look at why you chose that path (hopefully not because it was shiny and new). You show up when shit hits the fan and will wade through it until it’s stable again.
What accountability is not is blame. I run a blameless culture that looks for process flaws over people flaws. We don’t blame when things go wrong – we take ownership and action to prevent it from happening again.
Not all engineers like to be owners and accountable. With that comes many responsibilities like on-call, understanding where the business makes its money and how, doing your testing and self-checking, and trust in your team.
On Call
Ideally, you should never be called out for an incident. In an ideal world, bugs would not happen, and there would be no system failures. We’ve seen even the largest of organizations and engineering teams can have significant outages. But with ownership comes the dreaded on-call.
This should be like clockwork. No one should feel pressure and everyone should know their role and what to do in this situation. The most pressing concern is restoring the system. This usually means rolling back the latest change. The investigation into the issue can happen after. We want a standard functioning system so we don’t burn too much money.
In this case, every engineer should be on a rotation system for their team’s product with the leader of the product engineering team as the incident manager (this could even be the head/director of engineering). With well-defined roles ahead of time and practice/chaos engineering, it won’t seem so scary when it happens.
So, what is a product engineering strategy? Everything. It’s your technical, people, and cultural strategies. It’s also the processes you put in place and the tactics you use. It’s how you sell your team to stakeholders and define your investment.
I’ve tried to put a lot of thought into words in this post. I’ve likely missed something important I’ll bring up in a future article. I’d like to thank Wijayawati Yip for helping to review this for me. It’s a long read!
Clear and practical guide on aligning product engineering strategies with business goals to ensure scalable and reliable solutions.