

Prompt engineering is often talked about like it’s magic.
Write the right words. Add the right examples. Tell the model to be careful. Tell it to think step by step. Tell it not to hallucinate. Tell it to output JSON. Tell it to be concise. Tell it to be accurate. Tell it to do everything. Add some pixie dust and et voilà.
And, to be fair, sometimes that works. At least for a demo.
But once you put AI into a real product, the prompt stops being a clever paragraph and starts becoming production logic. You cannot prompt your way out of unclear instructions.
The lesson was simpler than I expected: the prompt was trying to do too much.
In normal code, we know this smell immediately. One thing is doing too much. It has too many reasons to change. Every fix risks breaking something unrelated.
The same thing can happen to prompts.
This post is about that refactor. I’ll keep the implementation details out of it, because the useful lesson is more general: production prompts need software design.
The first version was one big prompt
The first version was obvious. It was also very easy to get to a convincing demo. Demo-god ready, basically. The first goal was to prove the workflow could work. The reliability work came after that.
We had an expense review workflow. We had a model. We had context about the expense. We had policy information. We had supporting evidence. So we gave the model everything.
The prompt basically said:
Here is the expense. Here is the policy. Here is the supporting information. Tell us whether anything is wrong.
That is not the real prompt, of course, but that was the shape of it. And at first, it felt reasonable. A human reviewer works like that. You look at the expense and you read the policy. You inspect the evidence and you decide whether something looks wrong.
So why not ask the model to do the same thing?
The problem is that models are not human reviewers. They are very sensitive to the shape of the task. If you ask them to do too many things at once, they can still produce an answer, but it becomes harder to know whether the answer is grounded in the right reasoning.
That was the first smell. The model usually produced something plausible. But plausible is not the same as reliable. Reliability was the part that mattered.
The prompt had too many jobs
As the workflow grew, the prompt grew with it.
We added more instructions. Then more edge cases. Then more formatting rules. Then more things to avoid. Then more examples. Then more reminders that one kind of issue should not be confused with another kind of issue.
You can probably guess what happened.
The prompt became a wall of text. It was hard for a human to reason about, let alone an LLM.
It had to reason about policy. It had to reason about evidence, dates, and amounts. It had to reason about required context. It had to decide whether the issue mattered and what status to return. It had to explain the result in a user-friendly way. The list goes on…
That is a lot of responsibility for one prompt.
The first major problem was scope confusion. Sometimes the model would blur two different kinds of concerns. For example, one issue might really be about whether the supporting evidence can verify the expense. But the model could describe it as though it were a policy problem.
Those are not the same thing.
A policy concern says something like:
This appears to conflict with the rules.
A verification concern says something like:
We cannot confirm this from the available evidence.
That difference matters.
The customer needs to know what action to take. The workflow needs to know what should happen next. Engineers need to know where to look when the system gets it wrong.
It also matters for trust. In this kind of workflow, the output needs to be boringly reliable. As predictable as we can make it.
The second problem was debugging. When the model made a bad call, where did you look? Was the policy instruction too broad? Was the evidence instruction too vague? Was an example biasing the model? Did a formatting rule accidentally change the actual judgment? Did one paragraph contradict another paragraph?
It was hard to tell.
The third problem was regression risk. You would change one instruction to fix one issue, and then something unrelated would behave differently.
That is the moment when a prompt stops feeling like a prompt and starts feeling like a badly designed function. One function. Too many responsibilities. Too many reasons to change. We all know this smell in deterministic code. We just need to bring this into the AI world.
So we split the work apart
The refactor started with a simple question:
What are the independent judgments the system needs to make?
That question helped a lot. Instead of asking one model call to make every judgment at once, we split the workflow into smaller checks. Some checks were about policy interpretation. Some checks were about verification. Some were about whether the expense appeared to follow the rules. Others were about whether the submitted data could be reconciled with the available evidence.
I’m intentionally keeping this high level. The exact number of checks and the exact shape of the workflows vary by expense type and product flow. That level of detail is not the point of this post.
What I want to focus on is the boundary:
- A policy-oriented check should focus on policy.
- A verification-oriented check should focus on evidence.
A check about timing should not need to know everything about evidence matching. A check about supporting evidence should not need to interpret every possible policy rule. A check about required context should not need to solve unrelated consistency problems.
The decomposition also made it easier to see which parts genuinely needed model judgment and which parts did not.
Each check should have one job and that sounds obvious when you say it out loud. But a lot of prompt engineering work starts with the opposite instinct. We keep adding instructions to the same prompt because it feels faster. One more paragraph. One more warning. One more example. One more “do not confuse X with Y”. And it works… for a time.
Eventually the prompt becomes the thing you are fighting. Splitting the checks changed the system. It did not make the model perfect. Nothing does. But it made the behaviour easier to reason about.
Once each prompt had a narrower responsibility, the evals became narrower too. A failure was easier to attribute to a specific judgment rather than a large blob of instructions.
If a policy check was wrong, we could look at the policy prompt. If a verification check was wrong, we could look at the verification prompt. If a shared behaviour was wrong, we could look at the shared instruction block.
Way easier to debug at 8am on a Thursday before coffee.
The prompts started to look like code
Once the checks were split apart, another problem appeared: duplication.
Every check needed some common structure. Safety instructions. Output format. Status definitions. Common reasoning constraints. Then the specific instructions for that check.
We could have copied and pasted that into every prompt. That would have worked for about… five minutes.
Then one prompt would drift. Then another. One would have the latest wording. Another would have an older version. One would explain a status slightly differently. Another would forget an edge case.
Copy-pasted prompt text decays just like copy-pasted code.
So we treated the prompts more like code. There was a shared structure, and each check filled in only the part that was unique to its job. Remember DRY?
The structure was shared. The judgment was specific.
That is basically the Template Method pattern, but for prompts. Not revolutionary. Almost boring. But boring is usually what you want in production.
Shared instruction blocks helped reduce drift
The next step was extracting shared instructions. As the prompts matured, we kept seeing the same kinds of guidance appear in multiple places.
- How should the model treat structured data compared with free-text notes?
- How should it avoid mixing policy concerns with verification concerns?
- How should it behave when evidence is incomplete?
- How should it avoid exposing internal implementation details?
- How should it format the result consistently?
- How should it define statuses consistently?
At first, it is tempting to just repeat those instructions wherever they are needed. But again, that creates drift. So we moved repeated guidance into shared instruction blocks.
Each check then composes the pieces it needs. A policy-related check might need policy hierarchy, exceptions, output format, and status definitions. A timing-related check might need date comparison and policy interpretation. A verification-related check might need evidence consistency, conservative reasoning, output format, and user-safe explanation rules.
The important part is that each check chooses only what it needs.
You do not want one giant shared instruction block that every check gets by default. That just recreates the monolithic prompt in a more complicated way.
Reusable is good. Universal is dangerous.
Shared instruction blocks gave us consistency without forcing every check to carry every instruction. It also made fixes safer. If a common instruction was wrong, we could fix it once. Every check that depended on that instruction would get the fix.
Again, this is not exotic. It is a utility library. For prompts. Simple.
We separated evaluation from presentation
This was another big lesson. At first, the evaluation prompt had to do everything. It had to decide what was true, and it had to explain that result nicely to a user. That sounds small, but it is actually two different jobs.
The evaluator should answer:
What appears to be happening?
The presentation layer should answer:
How do we explain that clearly, safely, and consistently?
Those are not the same thing.
The raw model output might contain details that are useful for internal reasoning but not appropriate for the user. It might include machine-oriented language. It might repeat the same concern in two different ways. It might use wording that does not quite match the final status. It might need localisation.
So we moved that cleanup into a separate transformation layer. I’m intentionally not listing the exact internal pipeline here. The shape matters more than the implementation.
The transformation layer handles things like:
- removing internal implementation details from user-facing text
- stripping machine-oriented metadata and jargon
- deduplicating repeated concerns
- keeping the output aligned with the responsibility of the check
- making sure the reasoning matches the final status
- localising the message when needed
This made the evaluation prompts simpler. They no longer had to carry the full burden of product presentation. They could focus on the judgment. Then the transformation layer could focus on making the result safe and understandable.
Same old separation-of-concerns lesson, just applied to LLM output.
The architecture became easier to explain
The old version looked something like this:
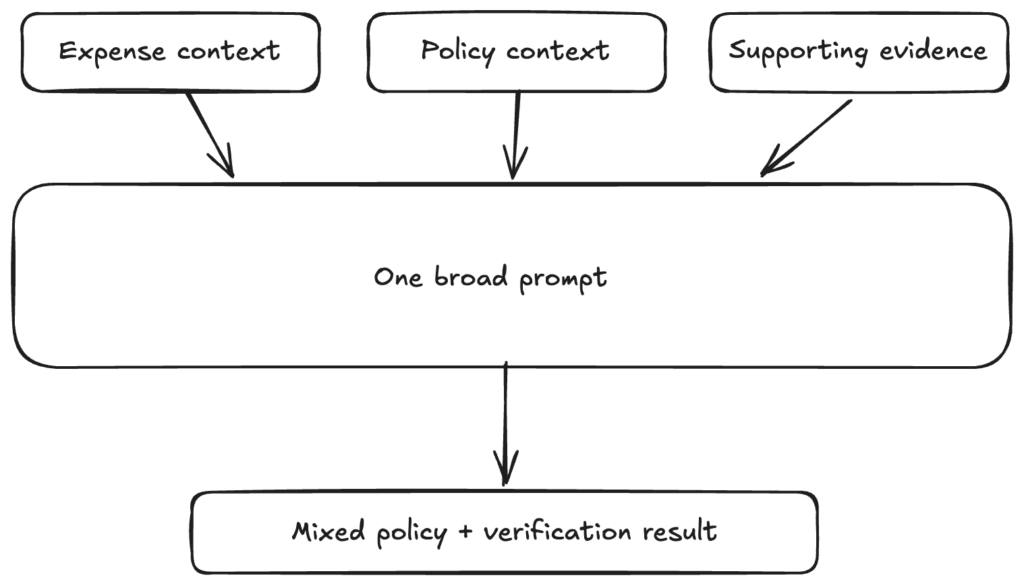
The newer version looks more like this:
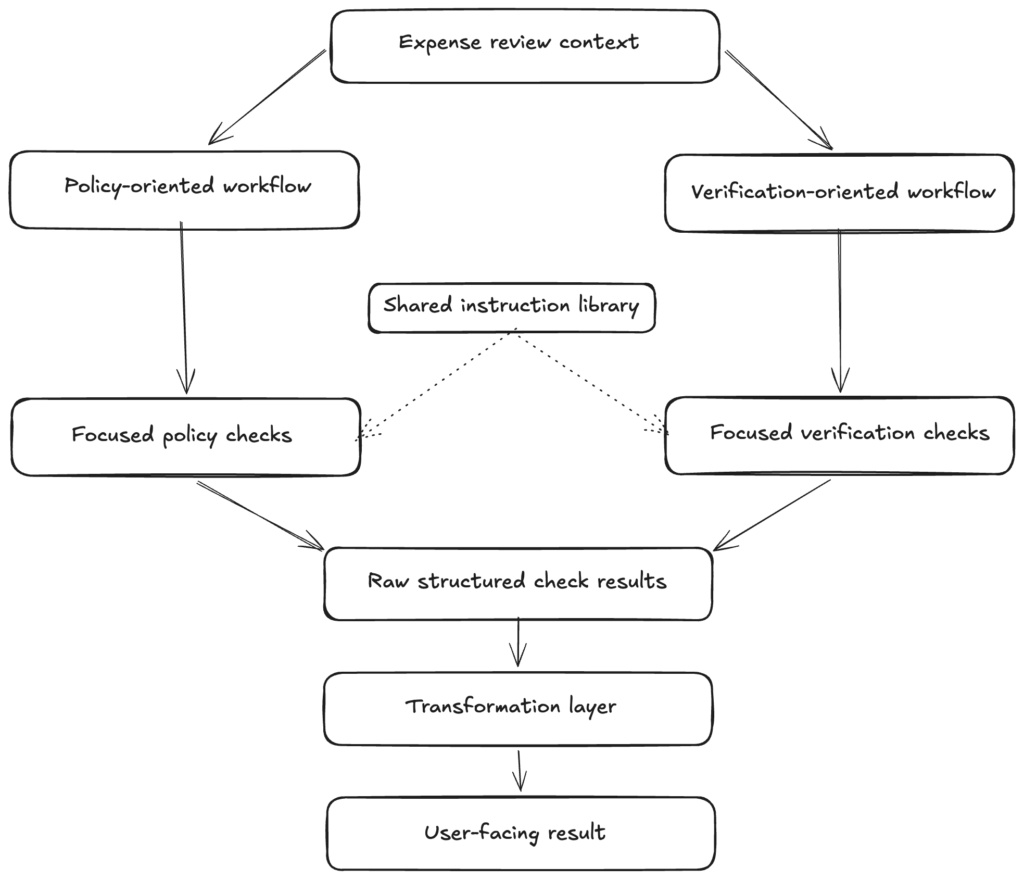
This is deliberately simplified. But I think simplified diagrams are useful because they show the actual idea.
- The idea is not “use lots of agents”.
- The idea is not “make the prompt longer”.
- The idea is not “add more clever instructions”.
The idea is to separate responsibilities. Each LLM call has one task to solve, and each layer has a clear job before handing off to the next one.
What I learned
Smaller prompts are easier to evaluate
When a prompt has one job, the eval suite becomes easier to reason about. A policy eval should fail because the policy judgment is wrong. A verification eval should fail because the verification judgment is wrong.
With a monolithic prompt, failures are muddy. You end up asking, “Which part of this giant thing caused the problem?”
With decomposed prompts, failures are more attributable. That does not make debugging easy. But it makes debugging possible.
Prompt changes are code changes
A one-line prompt change can change production behaviour. It can change how the model interprets policy and how conservative it is. It can change what it chooses to mention and the final status.
That means prompt changes need the same kind of discipline as code changes. You need to know what changed, why it changed, and what behaviour you expected to change. You need to know what behaviour should not have changed. That also means prompt changes need to be versioned and evaluated like any other production logic change.
I used to think of prompts as configuration. I now think of them more like product logic. Like the business layer in a monolithic application.
Shared instructions prevent drift
Copy-pasted prompt text is a trap. It feels harmless in the beginning. Then the copies drift. Then the behaviour drifts. Then nobody is quite sure which prompt has the correct version of the instruction.
Shared instruction blocks help. But only if they stay small and focused. If the shared block becomes too broad, you have just created a monolith with extra steps.
Evaluation and presentation should be separate
This was probably the most product-relevant lesson. The model output that is useful for evaluation is not always the output you want to show a user. The user does not need implementation details. They do not need internal terminology. They do not need repeated concerns. They do not need wording that almost matches the status but not quite.
They need a clear explanation of what needs attention. That is a presentation problem. It should not contaminate the evaluation prompt.
Boring engineering principles still work
There was nothing exotic about the most useful ideas. In fact, they’re the learnings we as software engineers have battle-tested and written books about: separate responsibilities, reduce duplication, make changes traceable, and keep behaviour testable.
You still need good software design and a few scars from maintaining real systems. If anything, it makes design more important, because the behaviour is less deterministic.
The less deterministic the component, the more structure you need around it.
Closing
The move from one giant prompt to focused checks did not make the system perfect. LLMs are still probabilistic. They still need evals, guardrails, fallbacks, and careful product design.
But the refactor made the system easier to reason about.
When a check fails, we know where to look. When an instruction changes, we know what should be affected. When shared behaviour needs to improve, we update a reusable instruction block instead of hunting through duplicated prompt text. When user-facing output needs polish, we adjust the transformation layer instead of contaminating the evaluator.
The answer was not a smarter magic phrase.
It was better structure.
The less deterministic the component, the more structure you need around it.
Leave a comment