

In the previous post, I wrote about deciding which parts of an expense workflow should be automated first.
Some decisions are better handled with ordinary code. Some need model judgement. Some should surface information for a reviewer without making the final call. Over time, the goal is to automate more of the workflow as the system earns enough trust.
But that creates another question:
How do you make the decisions that genuinely need an LLM reliable enough for production?
That is a harder problem than it first appears.
The user does not care whether the system technically hallucinated, misunderstood the policy, wandered outside the scope of the question, or produced a confident explanation that did not match its final conclusion.
From the user’s point of view, the distinction is simple:
The system got it wrong.
That matters because most users do not think about AI systems in terms of prompts, models, agents, or orchestration layers. They see one product. They expect it to work.
Improving the prompt helps. Clearer instructions help. Better examples help. Asking the model to return structured output helps.
But none of those things are enough on their own.
If an LLM is part of a production workflow, you need to assume it will occasionally do something strange. The engineering work is not pretending that will never happen. It is reducing the surface area for mistakes, validating what can be validated, and containing failures before they reach the user.
The answer is not one better prompt.
It is layers of protection around the model.
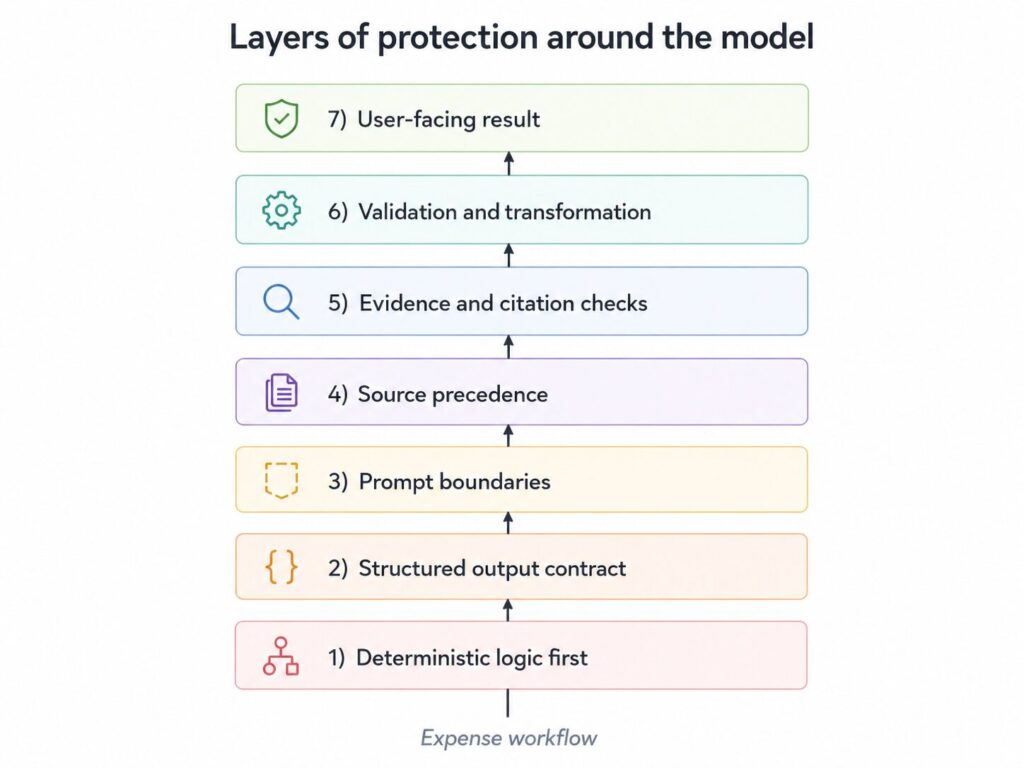
The cost of being confidently wrong
Our agent helps evaluate expenses against company policies and supporting evidence.
That is a useful place for an LLM. Policies are usually written for humans. They contain exceptions, vague wording, and rules that only make sense in context. Expense claims can also be messy. Work and personal spending can overlap. Receipts are imperfect. The boundary between a reasonable expense and a policy violation is not always obvious.
That is exactly why model judgement is useful.
It is also why being confidently wrong is dangerous.
If the system flags an expense incorrectly, an employee may need to explain something that was perfectly valid. A reviewer wastes time investigating a false positive. Trust in the product drops slightly.
But the cost of a false negative can be much higher.
If the system misses a real issue, something that should have been reviewed may move through the workflow unnoticed. That matters for companies relying on the product to enforce their own policies and financial controls. It matters even more as the workflow becomes increasingly automated and some cases move through without a human reviewing them at all.
The system cannot simply sound plausible.
Its decisions need to be obvious, boring, and reliable.
That means reducing the number of places where the model is allowed to improvise. It means preferring deterministic logic where possible. It means validating what can be validated. It means being honest when the evidence is ambiguous.
That is how you reduce the chance of the system being confidently wrong.
And that is how you earn trust.
Prefer codified rules over model instructions
The first layer is the simplest:
Do not call the model unless you need the model.
Wherever possible, prefer codified rules over model instructions.
If a value can be compared with a rule, compare it in code. If the workflow already knows whether a receipt is required, check that configuration directly. If a required field is missing, detect that before calling the model. If two pieces of structured data can be compared reliably, compare them directly.
The comparison does not always need to be an exact match. Ordinary code can still handle fuzzy cases: normalising strings, calculating edit distance, applying a date window, or using a numeric threshold to identify likely candidates.
Those rules may still be imperfect. But they are repeatable.
The same input produces the same output. We can write unit tests for the expected behaviour. When something breaks, we can reproduce the failure. When the rule changes, we can see exactly what changed.
That is harder with an LLM. Model behaviour can vary across runs, prompts, and model versions. Evals help, but they are not the same as a deterministic unit test.
There is also no reason to ask the model a question when the system does not have the information required to answer it.
That should be explicit in the application logic.
If an amount comparison requires two values and a currency conversion rate, check that those inputs exist first. If they do, run the comparison. If they do not, return an explicit fallback or surface the missing information for review.
Do not ask the model to improvise around missing data unless interpretation genuinely adds value.
Avoiding unnecessary model calls also reduces latency and cost. A model call involves a remote request, prompt processing, and token generation. A local rule or comparison avoids that work entirely.
But the biggest benefit is reliability.
Traditional code has a much smaller surface area for surprising behaviour. A comparison does not reinterpret the question. A lookup does not get distracted by an unrelated detail. A guard clause does not produce a persuasive explanation for the wrong conclusion.
The model should handle the smallest remaining part that genuinely needs judgement.
Nothing more.
Treat the model like an API
Once you decide that a question genuinely needs an LLM, the model response should be treated like an API response.
Do not ask for a paragraph and hope the application can work out what it means.
Define a contract.
The model should return a small number of clearly defined fields. The allowed states should be explicit. Required fields should actually be required. Unexpected fields should be rejected. Invalid responses should not silently pass through.
For example, the system may need a status, a short explanation, and a reference to the relevant evidence. It should not accept a new workflow state merely because the model decided to invent one.
Structured output removes an entire class of avoidable failures. Both OpenAI and Google document schema-constrained structured output for production-style workflows.
The model cannot bury the conclusion in three paragraphs of prose if the application expects a small structured response. It cannot quietly rename a field without the application noticing. It cannot add a new status that the workflow does not understand.
But a schema only solves part of the problem.
A schema can constrain the shape of the answer. It cannot guarantee that the answer is correct. Google’s documentation makes this distinction explicitly: structured output can guarantee syntactically correct JSON while the values may still be semantically wrong. OpenAI makes the same point: a response may follow the schema and still contain mistakes inside the values.
The model can still return a perfectly valid JSON response with the wrong status. It can still misunderstand the policy. It can still provide a plausible explanation for the wrong conclusion.
So the application still needs to validate what it can. If the model references a policy section, check that the section exists. If it claims required information is missing, verify whether the field is actually empty. If the response contradicts known structured data, reject it or send it for review.
The failure path should also be explicit. If the model refuses the request, returns an incomplete response, or produces a result that fails validation, the application should decide what happens next: retry, fall back to a safer path, or surface the case for review.
Treat the schema as the outer contract.
Then validate the meaning inside it.
The model still has freedom where freedom is useful. The rest should be constrained.
Give the model boundaries
When an LLM is needed, the next question is scope.
A vague question produces a vague answer.
If you ask whether an expense is “okay”, the model has a lot of room to decide what “okay” means. It might comment on the company policy, the receipt, the explanation, the timing, or something else entirely.
That may be useful in a chatbot. It is much less useful in a production workflow where the result feeds into a specific product action.
The challenge is that the underlying policy may itself be vague. Policies are written for humans. They contain exceptions, loose wording, and rules that depend on context. That ambiguity is often the reason we need an LLM in the first place.
The goal is not to remove all ambiguity.
The goal is to constrain the ambiguity the model is allowed to resolve.
A policy-oriented check should answer a policy question. A verification-oriented check should answer whether the available evidence supports the claim. A check about timing should not start commenting on the quality of a receipt. A check about supporting evidence should not invent a policy rule because the expense looks suspicious.
The model should not decide what problem it is solving. The application should decide that before the model is called.
Each call should have a clear boundary:
- What question is the model answering?
- Which inputs are relevant?
- Which inputs should be ignored?
- What conclusions is it allowed to return?
- What should it do when the available evidence is not enough?
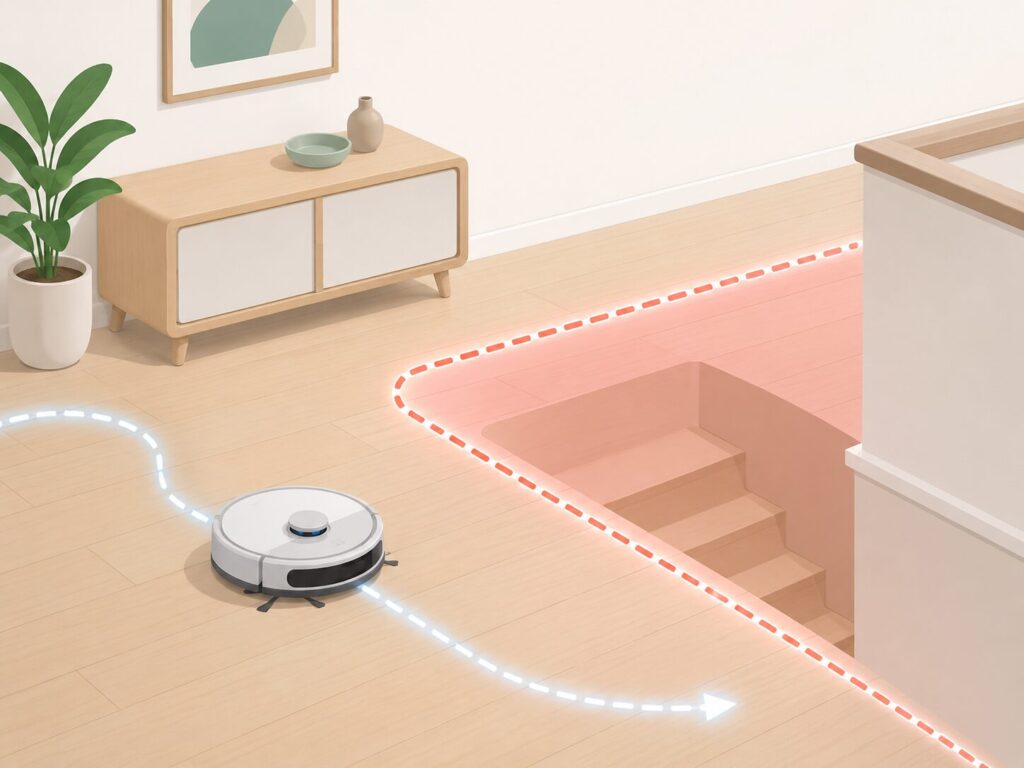
This is similar to setting a virtual boundary for a robot vacuum. The vacuum may be autonomous, but you still define where it is allowed to go. Without that boundary, it may wander into a room it should avoid or find the stairs in a less-than-ideal way.
An LLM needs the same kind of boundary.
We cannot eliminate every wrong turn. But we can reduce the space in which the model is allowed to wander.
The less room the model has to improvise, the easier the output is to trust.
Not all context is equally trustworthy
An expense workflow pulls information from a lot of different places.
There may be card transaction data, submitted expense fields, receipt OCR, policy documents, comments, and ML-generated suggestions.
They can all be useful.
But they should not all carry the same weight.
Some data is concrete. If the expense came from a company card, the underlying transaction data should generally be treated as the source of truth for fields such as the amount, currency, and transaction date.
Other data is extracted or user-provided.
Receipt OCR may contain errors. A comment may add important context, but it should not casually override a known transaction amount. An ML suggestion may be useful, but it is still a suggestion.
The model needs to understand those differences.
If two sources disagree, it should not simply choose the one that sounds more plausible. The application should make the hierarchy clear:
- which fields are authoritative
- which sources provide supporting evidence
- which sources are useful context
- which sources should be treated cautiously
This matters because free text is messy.
People write shorthand. Receipts contain noise. Descriptions can be incomplete. Comments may include irrelevant details. User-provided text can even contain instructions that the model should not follow.
The model should use that context where it helps with interpretation. But it should not be allowed to rewrite known facts.
The application needs to decide which sources are authoritative before the model is called.
Treat raw model output as untrusted input
Even after you constrain the model with codified rules, a schema, narrow prompts, and clear source precedence, the raw response should not go directly to the user.
Treat it like output from any other external dependency.
You would not normally take a raw database row, a third-party API payload, or an internal exception and render it directly in the UI. You validate it, map it into a user-facing shape, remove internal details, and make sure it is safe to show.
An LLM response should be treated the same way.
Even a well-scoped model can return output that is technically useful but unsuitable for a user. It may repeat the same concern twice. It may use internal terminology. It may mention implementation details that are irrelevant to the person reviewing the expense. It may drift outside the responsibility of the check. It may produce an explanation that does not quite match its final status.
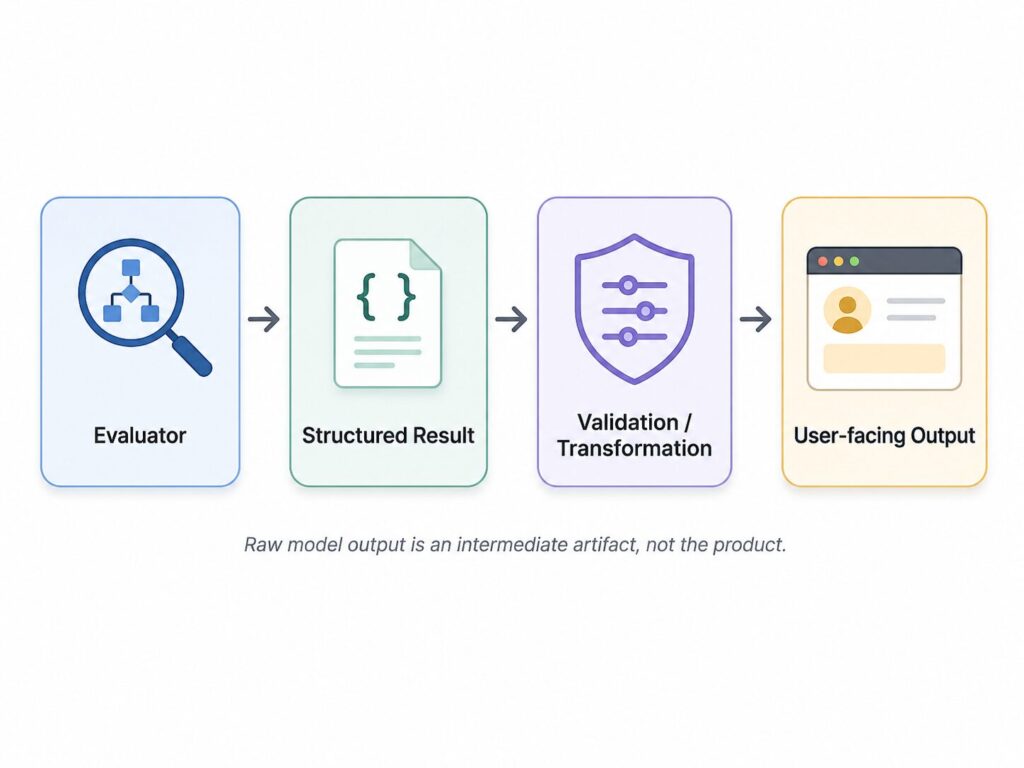
So the raw result goes through a transformation layer before it reaches the user.
The evaluator answers:
What appears to be happening?
The transformation layer answers:
How do we explain that clearly, safely, and consistently?
That separation is useful for more than presentation.
The transformation layer is another safety boundary. It can remove noise, deduplicate repeated concerns, catch contradictions, keep the explanation within scope, and reduce the chance that the system presents an uncertain conclusion with too much confidence.
But it is important not to overstate what this layer can do.
It cannot turn a fundamentally wrong conclusion into a correct one. If the model misunderstood the policy or reached a conclusion that conflicts with known data, the system needs to reject the result, fall back to a safer path, or surface the case for review.
The raw model result is an intermediate artifact.
It is not the product.
Make the model show its work
A model should not be trusted simply because its answer sounds plausible.
A good human reviewer would not flag an expense and leave it at that. They would point to the relevant policy rule, explain what evidence they considered, and show how they reached the conclusion.
The agent should do the same thing.
If the model says an expense breaches a policy, it should identify the relevant policy section. If it says required information is missing, the application should be able to check whether the field is actually empty. If it says the available evidence does not support the claim, the user should be able to understand what evidence was considered.
The broader principle is simple:
Use the model for interpretation. Use the system around the model for verification.
This is especially important for citations.
A fabricated policy reference is worse than no policy reference. It creates false confidence. The answer looks grounded even though the supporting evidence does not exist.
So citations should be treated like any other model output: validate them before showing them to the user.
Does the referenced section exist? Does it belong to the relevant policy? Does the cited evidence support the type of claim being made?
The application may not be able to prove that every interpretation is correct. That is why model judgement is still involved.
But it can verify that the answer is grounded in real evidence.
The model should not merely sound confident. It should show its work.
In financial workflows, “trust me” is not a useful audit trail.
Allow the system to be uncertain
There is another temptation when building AI workflows: forcing every result into a confident answer.
Product teams usually prefer clean states. Engineers usually prefer predictable branching logic. Users usually prefer clarity.
But sometimes the available information is genuinely ambiguous.
The system should be allowed to say that.
There is a difference between:
This expense violates policy.
and:
We could not verify this expense from the information available.
The second answer may be less satisfying, but it is also more honest.
That matters because uncertainty is not the same thing as failure.
If the evidence is incomplete, the correct response may be to ask for more information, surface the case for review, or avoid making a strong claim altogether.
Forcing a confident answer does not make the system more useful. It just increases the chance of being confidently wrong.
There is also a product cost to over-flagging.
If every ambiguous case becomes a warning, reviewers quickly stop paying attention. The warnings become background noise. The same thing happens with banners, notifications, and security alerts: once users expect noise, they stop noticing the signal.
Conservative defaults are not a weakness. They are a way of preserving attention for the cases that actually matter. And they are part of earning the right to automate more later.
Turn mistakes into evals
The guardrails reduce the chance of the system being confidently wrong.
They do not eliminate it.
A production AI system will still make mistakes. A policy may be ambiguous. The available evidence may be incomplete. The model may interpret a rule differently from a human reviewer. A result may look reasonable until someone with more context points out why it is wrong.
The important part is making those failures useful.
When a reviewer disagrees with the system, we need to understand why. Was the underlying data incomplete? Did the model apply the wrong policy rule? Did it rely on the wrong source of information? Was the conclusion correct but the explanation confusing? Did the system express too much certainty when the evidence was ambiguous?
Those are different failure modes. They need different fixes.
Another paragraph in the prompt will not fix missing data. A better transformation layer will not fix a bad policy interpretation. A stricter schema will not help if the system asked the wrong question in the first place.
The system needs enough observability to reconstruct what happened: the inputs it received, the evidence it considered, the decision it returned, and any validation or transformation applied before the result reached the user.
Then the failure should become part of the evaluation set.
That is how the system improves.
A reviewer correction is not merely an operational inconvenience. It is a new test case. It tells us where the boundary of the system currently sits and whether a future change actually makes the product better.
This matters because trust is not built by claiming the agent is accurate.
Trust is built by making mistakes visible, learning from them, and reducing the chance of repeating them.
Closing
You do not reduce hallucinations with one magic instruction.
You reduce them by treating the model like an unreliable dependency inside a larger system.
Prefer deterministic logic where possible. Give the model a narrow job. Constrain the output. Verify what can be verified. Transform the result before a user sees it. Turn mistakes into evals.
The model will still occasionally surprise you. That is part of working with probabilistic systems.
The engineering work is making sure those surprises do not become the user’s problem.
Leave a comment